本篇大綱#
本篇僅會出現在此 Blog,因為碰到 Volume Type __DEFAULT__ 有某些原因被管理員宣告 Retired,因此做了遷移相關紀錄。
題外話#
文章開始之前先岔題一下,我的《關於我怎麼把一年內學到的新手 IT/SRE 濃縮到 30 天筆記這檔事》系列文章被 iThome 評審團隊選為佳作,特此感謝評審的青睞,謝謝 Cloud Native Taiwan User Group 給予的 Infra Labs 還有郭靖前輩的協助,讓我可以把這文章順利寫完。
自己正在做生涯蠻大的規劃,預計要到年中才會公布,就敬請期待啦!
內文#
前幾天收到郭靖前輩的訊息,之前的預設 Volume type 是 __DEFAULT__,因為要把 __DEFAULT__ 給 retired,想要 Migrate 過去到 SATA_SSD。
具體有兩種做法:
- 用 CSI volume cloning 複製 PVC 然後切換過去,目前預設新建的 Volume type 應該都是
SATA_SSD。 - Detach 該 volume 然後用 Cinder 換成新的 Volume type。
最近鐵人賽的結果出爐,可以把該資源釋放來做其他事情了,但也剛好接到這樣遷移需求,因此裡面的服務也充當了這次的實驗白老鼠。
服務與架構介紹#
Kubernetes cluster 由 k8s-m0, k8s-n0, k8s-n1 組合而成,也就是一個 Master node 和兩個 Worker node 組合,裡面安裝了 Prometheus, Grafana, Loki, GitLab。
其中,使用到 PersistentVolume 的服務有
PrometheusGitLabGitalyPostgreSQLMinIORedis
Loki(理論上也需要,但鐵人賽期間我忘記要幫它用 PersistentVolume,所以它現在用的是 EmptyDir。)
轉換 Volume type#
因為要把硬碟 detach,為了避免服務直接損壞,這裡會先把節點關機後再做 detach,最後再更換 Volume type。
- 除了要關機的節點以外,把每個 Node 都做 Cordon。
這裡我會先把每個節點都做 Cordon,所有 Pod 都會待在原地不移動到其他的 Node 上。
kubectl cordon k8s-m0 # 如果 k8s-m0 要關機就不要打這行
kubectl cordon k8s-n0 # 如果 k8s-n0 要關機就不要打這行
kubectl cordon k8s-n1 # 如果 k8s-n1 要關機就不要打這行- 把該節點關機。
ubuntu@bastion-host:~$ ssh ubuntu@k8s-n0
ubuntu@k8s-n0:~$ sudo shutdown -h 0
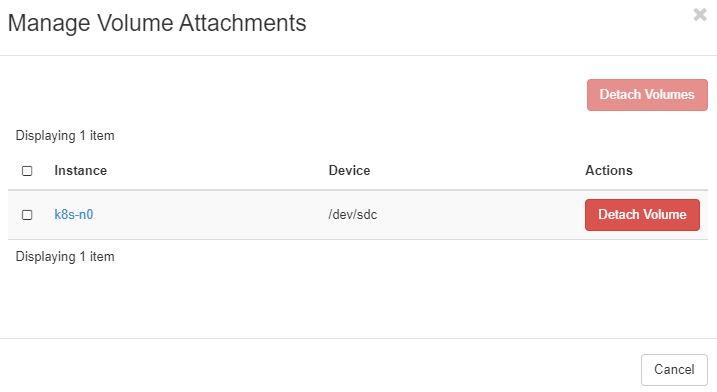
ubuntu@bastion-host:~$- 把該節點上的硬碟 detach
選硬碟 > Manage Attachments
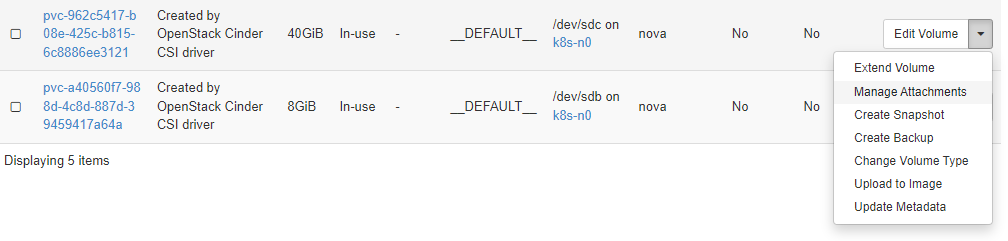
點選 Detach Volume。
- 更換 Volume Type
選硬碟 > Change Volume Type
- Type:
SATA_SSD - Migration Policy:
On Demand
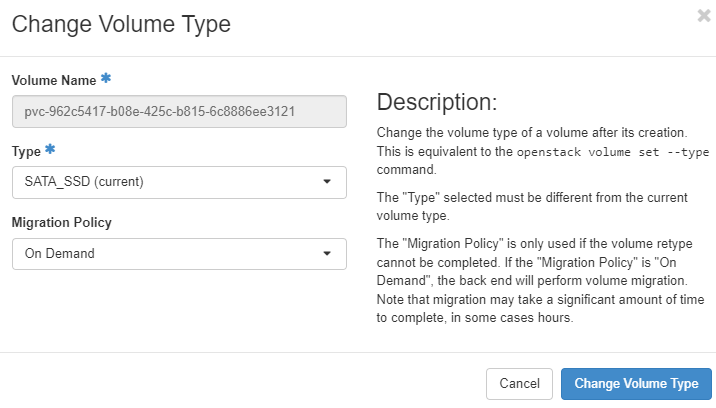
點選 Change Volume Type。
等待轉換
轉換完成後,重新 attach 到該節點上。
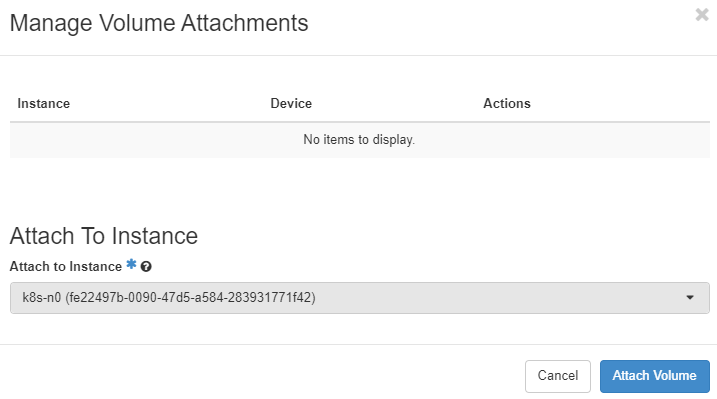
重新開機該節點
把每個 Node 都做 Uncordon
kubectl uncordon k8s-m0
kubectl uncordon k8s-n0
kubectl uncordon k8s-n1小插曲 - Application Credentials#
這次在更換時還出現小插曲,因為我之前專案分很多隻帳號,實驗帳號有掛 Application Credentials,整合後 Application Credentials 沒有一起合併,因此還出現 CSI 全部直接 Crash。

ubuntu@bastion-host:~/k8s/cinder-csi$ kubectl logs -n kube-system openstack-cinder-csi-nodeplugin-dhvbx cinder-csi-plugin
I1222 11:32:21.780001 1 driver.go:75] Driver: cinder.csi.openstack.org
I1222 11:32:21.780073 1 driver.go:76] Driver version: 2.0.0@
I1222 11:32:21.780080 1 driver.go:77] CSI Spec version: 1.3.0
I1222 11:32:21.780113 1 driver.go:107] Enabling controller service capability: LIST_VOLUMES
I1222 11:32:21.780122 1 driver.go:107] Enabling controller service capability: CREATE_DELETE_VOLUME
I1222 11:32:21.780128 1 driver.go:107] Enabling controller service capability: PUBLISH_UNPUBLISH_VOLUME
I1222 11:32:21.780136 1 driver.go:107] Enabling controller service capability: CREATE_DELETE_SNAPSHOT
I1222 11:32:21.780141 1 driver.go:107] Enabling controller service capability: LIST_SNAPSHOTS
I1222 11:32:21.780148 1 driver.go:107] Enabling controller service capability: EXPAND_VOLUME
I1222 11:32:21.780155 1 driver.go:107] Enabling controller service capability: CLONE_VOLUME
I1222 11:32:21.780161 1 driver.go:107] Enabling controller service capability: LIST_VOLUMES_PUBLISHED_NODES
I1222 11:32:21.783368 1 driver.go:107] Enabling controller service capability: GET_VOLUME
I1222 11:32:21.783405 1 driver.go:119] Enabling volume access mode: SINGLE_NODE_WRITER
I1222 11:32:21.783413 1 driver.go:129] Enabling node service capability: STAGE_UNSTAGE_VOLUME
I1222 11:32:21.783420 1 driver.go:129] Enabling node service capability: EXPAND_VOLUME
I1222 11:32:21.783424 1 driver.go:129] Enabling node service capability: GET_VOLUME_STATS
I1222 11:32:21.783468 1 openstack.go:137] InitOpenStackProvider configFiles: [/etc/kubernetes/cloud.conf]
I1222 11:32:21.794251 1 openstack.go:90] Block storage opts: {0 false false}
W1222 11:32:21.930439 1 main.go:100] Failed to GetOpenStackProvider: Resource not found: [POST https://openstack.cloudnative.tw:5000/v3/auth/tokens], error message: {"error":{"code":404,"message":"Could not find Application Credential: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.","title":"Not Found"}}這時候照我的 {% post_link it2022-day23 Day 23 Cinder CSI Plugin %} 重新設定 OpenStack Application Credentials 即可。
Zero downtime 的可能性#
這裡我有跟郭靖前輩小小請教,Change Volume Type 的 Zero downtime 可能性,但有點可惜的是服務都是 Stateful 而非 Stateless,要做 Zero downtime 本來就很麻煩。
後記#
雖然系列文結束了,但我還會不定時推出番外篇做更新,針對 Infra Labs 相關內容做調整。
下篇文章應該會來寫寫心得,有興趣可以按下 RSS 追蹤,那就下一篇文章見!